Damage detections and classifications using Machine Learning and Computer Vision.



The process of inspecting vehicle damages is one of the most important metrics that affects vehicles price, the manpower and the time spent could be costly as well as lengthy. An inspector needs to specify the damage type and also the level of it (deep, slight, moderate), it’s currently based on the human objectiveness for damages, which varies from one inspector to another, based on their level of expertise and knowledge.
In this fast paced business, using an inspector own personal judgement solely, could result a huge loss of time and revenue. Our solution promises to inspect, classify and estimate damages accurately and consistently.
Given the latter problem statement and currently used inspection process, we found that we have an opportunity to provide an automated solution for damage detections based on Computer Vision and Machine Learning.
In our journey, we found that to achieve high accuracy, the Machine Learning training sets need to be large, diverse, and accurately annotated, although, multiple solutions might be used to reduce the cost and time and increase the accuracy, such as image augmentation. Also, we found that collecting damages from various angles makes the results better so, we made a custom image collecting application to streamline the process by the users.

Solution Overview
We’ve decided that we can use Machine Learning and Computer Vision to provide Magical Black Box in order to detect all types and levels of damages in any given vehicle’s image or video stream.
While keeping in mind the need to use these images and/or video streams later by a mobile device or a back-end system for powerful usage of GPUs.


Solution's Architecture

Dataset collecting and Preprocessing
Image enhancements and filters are applied on the dataset images, usually Gaussian blur for noise reduction, Gamma correction and Histogram equalization.
The aim of pre-processing is an improvement of the image data that suppresses undesired distortions or enhances some image features relevant for further processing and analysis task.

Training preparation stage
In training preparation we propose the damages component category training dataset the involves the environment changes, such as lighting environment and applied image enhancements.

Training Stage
After adjusting the dataset with more than 1000 unique damage images we start the process of training our machine learning model to adjust the weights.

Detection and evaluation Stage
The obtained weights are evaluated based on the training metrics and the outputs from the detection module, on a known images (Validation Images) and new unknown images for the model.

Technical Decisions
Technologies used:
We needed to decide the usage of alot of technologies for the rest of research, more specifically the technologies used in machine learning, image processing, and image collecting.
For machine learning stage we’ve decided to use YOLO (You only look once) state of the art object detector, The YOLO algorithm is a typical one-stage target detection algorithm that combines classification and target regression problems with an anchor box, thus, achieving high efficiency, flexibility and generalization performance.
We’ve choose to use Python Tensorflow implementation of YOLO instead of the original one in C, the reason of this decision is to minimize the programming language barrier for our machine learning engineers.
Since most of machine learning applications require image preprocessing for better training results, we have choose to use OpenCV since it’s one the best computer vision libraries available.
Data collection is the most crucial step in machine learning, in order to effectively use machine learning techniques to solve any business problem. For damages collection and dataset construction, special in-house software is used to collect damages which we will discuss in the following section.
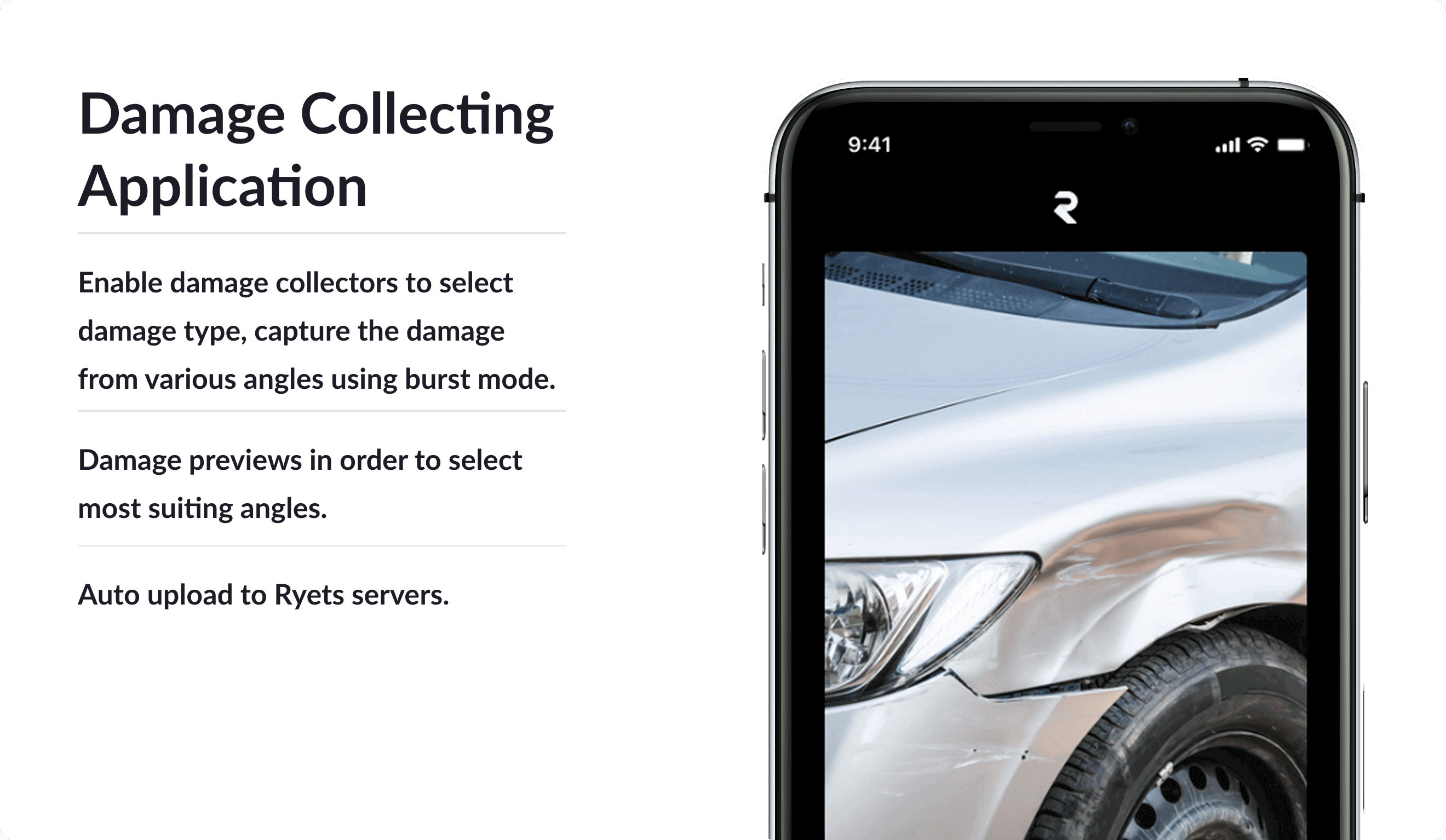
In-House Data Collecting Mobile application
One of our goals since day one is to make our model performant with various light conditions and various capturing angles, and in order to achieve this goal we’ve created a special mobile app to be used only for this purpose, where our data collectors seemingly collect damage scenes.

In the App, a collector selects the damage type they are going to capture, and the app immediately taking a stream of images for the damage while the collector is moving his hand slightly and changing the angles, after finishing the process of taking these batch images, about 20~ 30 image are selected and sent to our servers at the end of the day, the following process boosted the process of collecting damages by milestones.
The images are saved on our servers so we can start working on them for machine learning stage.
Technical Implementation
Great, now we have images needed for dataset, some image enhancements are applied on it, using open CV, then we start working on the process of machine learning.
which is consisted from:
1. Specify dataset Labels
2. Image labeling
3. YOLO Training
Dataset Labels
This is all about asking ourselves: What are we trying to detect in these images? Since we are interested in specifying damages, we have selected the following labels to be detected:
Image labeling
After deciding the labels we are interested in we can start labeling our images. for image labeling we are using
LabelImg
To start working with LabelImg, the followings will be executed:

After placing labels in Data/predefined_classes.txt
We can start labelling our images, where the output for each image will be a normalized coordinates that represent the position of bounding boxes and their classes.
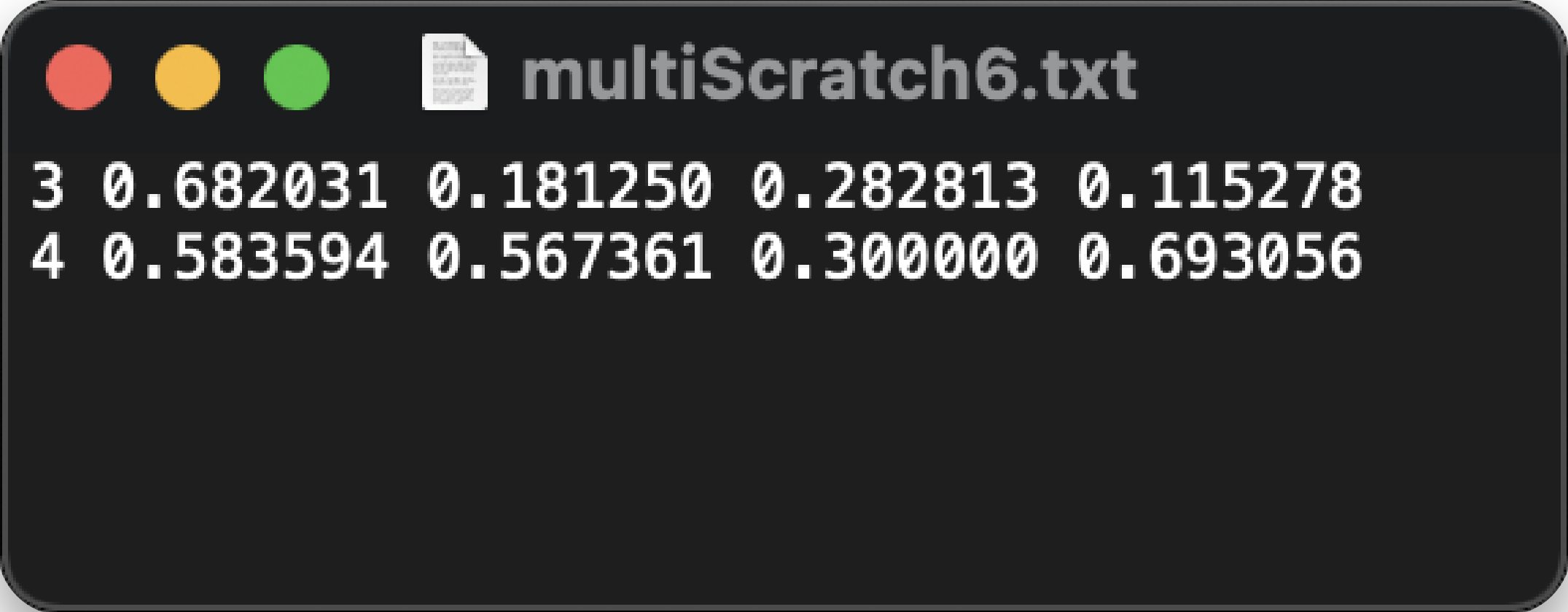
Labelimg is doing very good at labelling images without sacrifices the privacy of our datasets because other labelling tools are cloud based, which isn’t possible to be used in our case.
YOLO Configuration
Yolo is designed to be easy to setup and use, we’ve used Google Colab to benefit from the High speed GPUs. It needs to know which images should be used for training, and which for verification, and also the labels that were used while labelling the images, which can be specified in the data.yaml file.

Results
After adjustments and trials on the machine learning stage and Image enhancements, we were able to reach to initial satisfactory results.



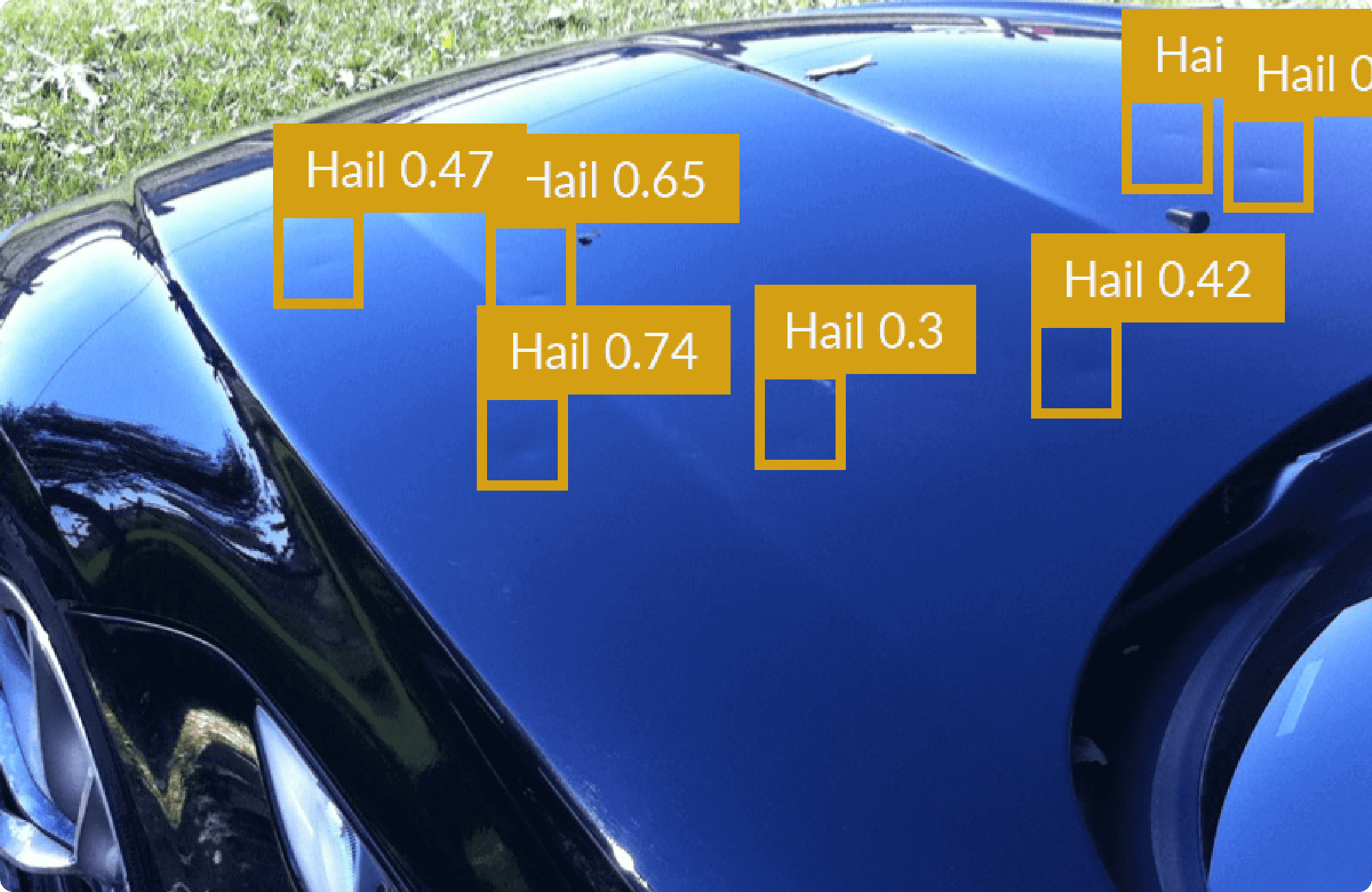
Technical Enhancements
For the technical enhancements we are planning to train our model with even larger datasets and enhance the current neural network, also we are experimenting on using YOLO C implementation instead of the python as it is expected to provide more speed.
Python is slow because it lacks integer types which corresponds to native integers which makes all integer operations vastly more expensive, also the lack of static typing (which makes resolution of methods more difficult, and this means the types of values must be checked at runtime).
Though the limitation of python’s performance was indeed a better option to start with.
Future Work.

We do strongly believe at Ryets that we can leverage from the power of machine learning and computer vision, in order to provide our customers unique and smart solutions for their problems, as well as providing best in class experience to make people’s life easier. There are countless usages for the trained model, for example: Augmented Reality is one of the emerging fields that changes the way we intercept the world and widely supported at nowadays mobiles, where an inspector would be able to see an augmented reality scene, where the vehicle is being processed and inspected, and where they can later save the inspection of the car and preview it on 3D models or on photogrammetry 3D models scanned from the vehicle images.
To provide best experiences for our users the model can be used from a mobile app where the detection can be achieved online on back-end powered by the Tesla V100 GPUs or offline if the internet connectivity is not stable.
Despite these groundbreaking developments, to this day the task of deciding the “correct” damage types remains ambiguous. While there is constant scope for evolution, at Ryets we believe one thing is certain — Any attempt to detect damages must be as correct as if it was done by an inspector, and as fast as possible, to achieve customer satisfaction.
Share article

Computer vision and machine learning for Damage Detection
Download all images


